Vue d'ensemble: Avec autant de cadres de développement autour de, il devient important que nous devrions être en mesure d'intensifier notre application à tout moment donné. Machine de techniques telles que le regroupement et la catégorisation d'apprentissage sont devenus populaires dans ce contexte. Apache Mahout est un cadre qui nous aide à atteindre l'évolutivité.
In this document, Je vais parler de Apache Mahout et son importance.
Présentation: Apache Mahout est un projet open source d'Apache Software Foundation ou ASF qui a l'objectif principal de la création de la machine algorithme d'apprentissage. Présenté par un groupe de développeurs du projet Apache Lucene, Apache Mahout a pour but de -
- Créer et soutenir une communauté d'utilisateurs ou contributeurs de sorte que l'accès au code source du cadre ne se limite pas à un petit groupe de développeurs.
- Focus sur les problèmes pratiques, plutôt que des questions inédites ou non prouvées.
- Fournir la documentation appropriée.
Caractéristiques de Apache Mahout:
Apache Mahout est livré avec une gamme de caractéristiques et de fonctionnalités en particulier quand on parle de Clustering et filtrage collaboratif. Les caractéristiques les plus importantes sont répertoriées comme sous -
- Goût filtrage collaboratif - Goût est un projet open source pour le filtrage collaboratif. Il est la partie du cadre Mahout qui fournit des algorithmes d'apprentissage automatique pour intensifier nos applications. Le goût est utilisé pour des recommandations personnelles. Ces jours-ci quand nous ouvrons un site Web, nous trouvons beaucoup de recommandations concernant le site que nous navigation. La figure suivante montre le schéma de l'architecture du Goût -
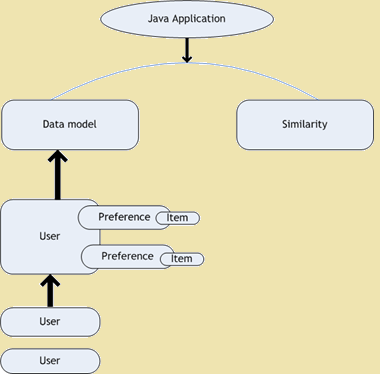
Dégustez Diagramme d'architecture
Figure 1: Dégustez Diagramme d'architecture
- Carte de réduire les mises en œuvre ont permis - Plusieurs carte Réduire les implémentations en cluster activés sont pris en charge dans Mahout. Ceci comprend K-moyenne, flou, Canopée
- Distributed Navie Bayes et gratuit Navie Bayes - mahout Apache a la mise en œuvre pour les deux Navie Bayes et gratuit Bayes. Pour la simplicité de Bayes Navie sont appelées Bayes et gratuit sont désignés comme CBayes. Bayes sont utilisés dans la classification de texte tandis que les CBayes sont l'extension de Bayes qui sont utilisés dans le cas des «datasets».
- Il prend en charge la matrice et d'autres bibliothèques de vecteurs connexes.
Mise en place d'Apache Mahout:
Mise en place d'Apache Mahout est très simple et peut être effectuée dans les étapes suivantes -
- Step 1 - Pour configurer Apache Mahout, nous devrions avoir le suivants installés -
- JDK 1.6 or higher
- Fourmi 1.7 or higher
- Maven 2.9 ou supérieur - Dans le cas où nous voulons construire à partir du code source
- Step 2 - Décompressez le fichier, sample.zip et copiez le contenu dans certains dossier disent "apache-cornac-exemples".
- Step 3 - Allez dans le dossier - "apache-cornac-exemples» et exécutez la commande suivante -
- ant install
La dernière étape télécharge les fichiers Wikipédia et compile le code.
Recommandation moteur:
moteur de recommandation est une sous-classe de l'information système de filtrage qui peut prédire l'utilisateur de notation ou les préférences peut donner à un élément. Mahout fournit des outils et des techniques qui sont utiles pour construire des moteurs de recommandation en utilisant la bibliothèque "Taste". Utilisation de la bibliothèque de goût, nous pouvons construire un moteur de filtrage collaboratif rapide et flexible. Le goût se compose des cinq principaux composants suivants qui travaillent avec les utilisateurs, articles et préférences -
- Modèle de données - Ceci est utilisé en tant que système de stockage pour les usagers, articles et aussi les préférences.
- Similitude de l'utilisateur - Ceci est une interface utilisée pour définir la similarité entre deux utilisateurs.
- Point Similarity - Une interface qui est utilisée pour définir la similarité entre deux éléments.
- Recommender - Une interface qui est utilisée pour fournir des recommandations.
- Quartier de l'utilisateur - Une interface qui est utilisée pour calculer et calculer un voisinage des utilisateurs de même catégorie qui peuvent être utilisées par le recommandataires.
L'utilisation de ces composants et leurs implémentations, nous pouvons construire un système de recommandation complexe. Ce moteur de recommandation peut être utilisé dans les deux recommandations en temps réel et des recommandations hors ligne. recommandations en temps réel peuvent gérer les utilisateurs jusqu'à quelques milliers, tandis que les recommandations hors ligne peuvent gérer les utilisateurs dans le nombre beaucoup plus élevé.
Clustering:
Mahout supporte de nombreux mécanismes de clustering. Ces algorithmes sont écrits dans la carte réduire. Chacun de ces algorithmes a son propre ensemble d'objectifs et de critères. Les importants d'entre eux sont répertoriés comme sous -
- Canopée - Ceci est l'algorithme le plus rapide de clustering utilisé pour créer des graines initiales pour d'autres algorithmes de clustering.
- k – Moyens ou k Fuzzy – veux dire - Cet algorithme crée k classes en fonction de la distance entre les éléments du centre de l'itération précédente.
- Moyenne - Shift - Cet algorithme ne nécessite aucune information préalable sur le nombre de clusters. Cela peut produire un cluster arbitraire qui peut être augmentée ou diminuée selon nos besoins.
- Dirichlet - Cet algorithme crée des clusters en combinant un ou plusieurs modèles de fragmentation. Ainsi, nous obtenons un avantage pour sélectionner le meilleur possible à partir d'un certain nombre de grappes.
Sur les quatre algorithmes ci-dessus énumérés, le plus couramment utilisé est le k - signifie algorithme. Que ce soit tout algorithme de clustering, nous devons suivre ces étapes -
- Préparer l'entrée. If required, convertir le texte en représentation numérique.
- Exécuter l'algorithme de votre choix en utilisant l'un des programmes prêts Hadoop disponibles dans Mahout.
- évaluer correctement les résultats.
- Itérer ces étapes si nécessaire.
Catégorisation du contenu:
Apache Mahout prend en charge les deux approches suivantes pour classer ou classer le contenu. Ceux-ci sont principalement basées sur la statistique bayésienne -
- La première approche est simple carte Réduire activé Navie Bayes classificateur. Classificateurs de cette catégorie sont connus pour être rapide et précis malgré l'hypothèse que les données sont complètement indépendants. Ces classificateurs se décomposent lorsque la taille des données monte ou données sont interdépendants. Navie bayes classificateur est un processus en deux parties qui garde une trace des caractéristiques ou simplement des mots qui associés à un document. Cette étape est connue comme la formation qui crée également un modèle en regardant des exemples de contenu déjà classé. La deuxième étape, connu sous le nom de classification, utilise le modèle qui est créé pendant la formation et le contenu d'une nouvelle, Document invisible. Par conséquent, afin d'exécuter le classificateur Mahout, nous avons d'abord besoin de former le modèle, puis utiliser le modèle pour classer le nouveau contenu.
- La deuxième approche, qui est également connu sous le nom complémentaire Naive Bayes, tente de corriger certains des problèmes avec l'approche Naive Bayes et maintient toujours la simplicité et la vitesse offerte par Navie Bayes.
Exécution de l'Navie Bayes Classifier:
Le Navie Bayes Classifier exige l'exécution des cibles ant suivantes afin d'exécuter -
- ant préparer-docs - Cela prépare l'ensemble des documents qui sont nécessaires à la formation.
- ant préparer-essai-docs - Cela prépare l'ensemble des documents qui sont nécessaires pour les tests.
- Train ant - Une fois les données de formation et de tests sont, nous avons besoin pour exécuter la classe TrainClassifier en utilisant la cible - «train de fourmi".
- test de fourmi - Une fois que les objectifs ci-dessus sont exécutées avec succès, nous avons besoin pour exécuter cette cible qui prend les documents d'entrée de l'échantillon et essaie de les classer en fonction du modèle qui a été créé pendant la formation.
Summary: Dans cet article, nous avons vu que Apache Mahout est largement utilisé pour la classification de texte en utilisant des algorithmes d'apprentissage machine. La technologie est encore en croissance et peut être utilisé pour différents types de développement d'applications. Résumons notre discussion sous forme de balles suivant -
- Apache Mahout est un projet open source d'Apache introduit par un groupe de développeurs du projet Apache Lucene. Objectif principal de ce projet est de créer l'algorithme qui peut lire le langage de la machine.
- Apache Mahout a les caractéristiques importantes suivantes -
- Goût filtrage collaboratif.
- MapReduce permis implémentations.
- La mise en œuvre à la fois Distributed Navie Bayes et gratuit Navie Bayes.
- Prise en charge de la matrice et d'autres bibliothèques à base vecteur connexes.