Übersicht: Mit so vielen Entwicklungs-Frameworks um, wird es wichtig, dass wir in der Lage sein sollte, unsere Anwendung zu einem bestimmten Zeitpunkt zu skalieren. Maschinenlerntechniken wie Clustering und Kategorisierung haben in diesem Zusammenhang populär geworden. Apache Mahout ist ein Framework, das uns Skalierbarkeit zu erreichen, hilft.
In this document, Ich werde über Apache Mahout und seine Bedeutung sprechen.
Einführung: Apache Mahout ist ein Open-Source-Projekt von Apache Software Foundation oder ASF, die das primäre Ziel hat der Schaffung Maschine Lernalgorithmus. Eingeführt von einer Gruppe von Entwicklern aus dem Projekt Apache Lucene, Apache Mahout hat das Ziel, zu -
- Bauen und eine Gemeinschaft von Nutzern oder Mitwirkenden unterstützen, so dass der Zugriff auf den Quellcode für den Rahmen ist nicht auf eine kleine Gruppe von Entwicklern begrenzt.
- Konzentrieren Sie sich auf die praktischen Probleme, anstatt ungesehen oder unbewiesene Fragen.
- Geeignete Unterlagen.
Merkmale von Apache Mahout:
Apache Mahout kommt mit einer Reihe von Features und Funktionalitäten vor allem, wenn wir über Clustering und Collaborative Filtering sprechen. Die wichtigsten Merkmale sind wie unter aufgeführt -
- Probieren Sie Collaborative Filtering - Geschmack ist ein Open-Source-Projekt für Collaborative Filtering. Es ist der Teil des Mahout Rahmen, der Algorithmen für maschinelles Lernen bietet unsere Anwendungen zu skalieren. Geschmack ist für die persönliche Empfehlungen verwendet. In diesen Tagen, wenn wir eine Webseite öffnen wir finden viele Empfehlungen mit der Website, die wir gerade sind. Die folgende Abbildung zeigt das Architekturdiagramm des Geschmacks -
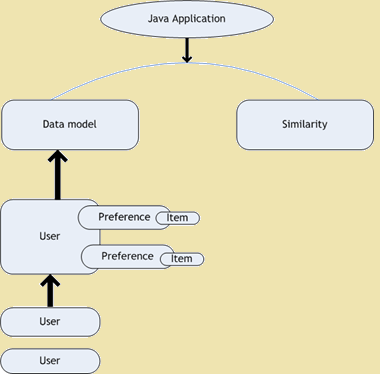
Probieren Architektur Diagramm
Figure 1: Probieren Architektur Diagramm
- Karte reduzieren aktiviert Implementierungen - Mehrere Karte aktiviert gruppierten Implementierungen reduce werden in Mahout unterstützt. Das beinhaltet K-mean, unscharf, Überdachung
- Navie Bayes und kostenloser Navie Bayes Distributed - Apache Mahout hat die Implementierung für beide Navie Bayes und kostenloser Bayes. Der Einfachheit halber Navie bayes als Bayes und kostenloser bezeichnet werden, werden als CBayes bezeichnet. Bayes werden in Textklassifikation verwendet, während die CBayes Verlängerung der Bayes sind, die im Fall von "Datensätzen" verwendet werden.
- Es unterstützt die Matrix und anderen verwandten Vektor-Bibliotheken.
Einrichten von Apache Mahout:
Einrichten von Apache Mahout ist sehr einfach und kann in den folgenden Schritten durchgeführt werden -
- Step 1 - Um Setup Apache Mahout, wir sollten die folgenden Anwendungen installiert -
- JDK 1.6 or higher
- Ameise 1.7 or higher
- Maven 2.9 oder höher - Im Fall, dass wir aus dem Quellcode zu bauen
- Step 2 Entpacken Sie die Datei -, sample.zip und kopieren Sie den Inhalt in einigen Ordner sagen "Apache-Mahout-Beispiele".
- Step 3 - In den Ordner gehen - "Apache-Mahout-Beispiele" und die folgende laufen -
- Ameise installieren
Der letzte Schritt lädt die Wikipedia-Dateien und kompiliert den Code.
Recommendation Engine:
Recommendation Engine ist eine Unterklasse von Systeminformationen zu filtern, die die Bewertung oder Präferenzen Benutzer kann zu einem Element geben kann vorhersagen. Mahout bietet Werkzeuge und Techniken, die hilfreich sind, um Empfehlungsmaschinen bauen mit Hilfe der 'Taste Bibliothek. Geschmack Bibliothek verwenden können wir eine schnelle und flexible Collaborative Filtering-Engine bauen. Geschmack besteht aus den folgenden fünf Hauptkomponenten, die mit Benutzern arbeiten, Artikel und Vorlieben -
- Datenmodell - Dies wird als ein Speichersystem für die Benutzer verwendet,, Artikel und auch Vorlieben.
- Benutzer Ähnlichkeit - Dies ist eine Schnittstelle verwendet, um die Ähnlichkeit zwischen zwei Benutzern zu definieren,.
- Artikel Ähnlichkeit - Eine Schnittstelle, die verwendet wird, um die Ähnlichkeit zwischen zwei Elementen zu definieren,.
- Empfehlender - Eine Schnittstelle, die verwendet wird, Empfehlungen zu geben.
- Benutzer Neighborhood - Eine Schnittstelle, die verwendet wird, zu berechnen und eine Nachbarschaft der Nutzer gleichen Kategorie zu berechnen, die durch die Recommenders verwendet werden kann,.
Mit Hilfe dieser Komponenten und deren Implementierungen, wir können eine komplexe Empfehlungssystem aufbauen. Diese Empfehlung Motor kann sowohl in Echtzeit Empfehlungen und Offline-Empfehlungen verwendet werden. Echtzeit-Empfehlungen kann der Anwender bis zu einigen tausend handhaben, während die Offline-Empfehlungen Benutzer in viel höheren Anzahl verarbeiten kann.
Clustering:
Mahout unterstützt viele Clustermechanismen. Diese Algorithmen sind in der Karte geschrieben reduzieren. Jeder dieser Algorithmen hat ihre eigene Reihe von Zielen und Kriterien. Die wichtigsten sind zu finden unter -
- Canopy - Dies ist die schnelle Clustering-Algorithmus zu schaffen anfänglichen Samen für andere Clustering-Algorithmen verwendet,.
- k – Die Mittel oder Fuzzy k – bedeutet - Dieser Algorithmus erzeugt k Cluster basierend auf dem Abstand der Elemente aus der Mitte der vorherigen Iteration.
- Mittlere - Verschiebung - Dieser Algorithmus erfordert keine vorherige Information über die Anzahl von Clustern. Dies kann eine beliebige Cluster erzeugen, erhöht oder verringert werden kann wie pro unser Bedürfnis.
- Dirichlet - Dieser Algorithmus schafft Cluster durch einen oder mehrere Clustermodelle kombiniert. Damit wir einen Vorteil bekommen die bestmögliche man von einer Anzahl von Clustern auszuwählen.
Von den vier oben genannten Algorithmen aufgelistet, das am häufigsten verwendete ist die k - bedeutet Algorithmus. Sei es jede Cluster-Algorithmus, wir müssen diese Schritte folgen -
- Bereiten Sie die Eingabe. If required, konvertieren Sie den Text in numerische Darstellung.
- Führen Sie den Algorithmus Ihrer Wahl, indem Sie eine der Hadoop bereit Programme in Mahout.
- Richtig beurteilen die Ergebnisse.
- Iterate diese Schritte, wenn erforderlich.
Inhalt kategorisieren:
Apache Mahout unterstützt die folgenden beiden Ansätze zu kategorisieren oder die Inhalte klassifizieren. Diese sind in erster Linie auf Bayes-Statistik basiert -
- Der erste Ansatz ist gerade nach vorne Map reduce aktiviert Navie Bayes-Klassifikator. Sichter dieser Kategorie sind schnell und genau zu sein bekannt, dass die Annahme, obwohl sie, dass die Daten vollständig unabhängig ist. Diese Klassifizierer brechen, wenn die Größe der Daten geht nach oben oder Daten werden voneinander abhängig. Navie Bayes-Klassifikator ist ein zweistufiger Prozess, der einen Überblick über die Funktionen oder einfach Worte hält, die mit einem Dokument verbunden. Dieser Schritt wird als Ausbildung bekannt, die auch ein Modell auf Beispiele von bereits klassifizierten Inhalte, indem Sie schafft. Der zweite Schritt, als Einstufung bekannt, verwendet das Modell, das während der Ausbildung und den Inhalt einer neuen geschaffen, ungesehen Dokument. Daher, um Mahout der Klassifikator zu laufen, müssen wir zunächst das Modell zu trainieren und dann das Modell verwenden, um neue Inhalte zu klassifizieren.
- Der zweite Ansatz, die auch als Complementary Naive Bayes bekannt, versucht, einige der Probleme mit der Naive Bayes-Ansatz und hält noch immer die Einfachheit und Geschwindigkeit angeboten von Navie Bayes zu korrigieren.
Das Ausführen des Navie Bayes Classifier:
Die Navie Bayes Classifier erfordert folgende ant-Ziele, um die Ausführung auszuführen -
- Ameise vorbereiten-docs - Dies bereitet den Satz von Dokumenten, die für die Ausbildung erforderlich sind,.
- Ameise vorbereiten-Test-docs - Dies bereitet den Satz von Dokumenten, die für die Prüfung erforderlich sind,.
- Ameise Zug - Sobald die Ausbildung und Prüfungen Daten gesetzt, wir brauchen die TrainClassifier Klasse mit dem Ziel zu führen - "ant Zug".
- ant-Test - Sobald die oben genannten Ziele erfolgreich ausgeführt, wir müssen dieses Ziel zu laufen, die die Probeneingabedokumente und versucht, nimmt sie auf dem Modell zu klassifizieren, die während des Trainings erstellt wurde.
Summary: In diesem Artikel haben wir gesehen, dass Apache Mahout weithin für Textklassifikation verwendet wird, durch maschinelles Lernen Algorithmen. Die Technologie wächst weiter und kann für verschiedene Arten von Anwendungsentwicklung verwendet werden. Lassen Sie uns unsere Diskussion in Form zusammenzufassen Kugeln von folgenden -
- Apache Mahout ist ein Open-Source-Projekt von Apache eingeführt von einer Gruppe von Entwicklern aus dem Apache Lucene Projekt. Hauptziel dieses Projektes ist es Algorithmus zu schaffen, die Maschinensprache lesen.
- Apache Mahout hat folgende wichtige Funktionen -
- Probieren Sie Collaborative Filtering.
- MapReduce ermöglicht Implementierungen.
- Implementierung für beide Distributed Navie Bayes und kostenloser Navie Bayes.
- Unterstützt Matrix und anderen verwandten Vektor-basierte Bibliotheken.