Přehled: S tolika rámců rozvojových kolem, to se stává důležité, že bychom měli být schopni rozšířit naše aplikace v daném okamžiku. Strojové učení technik, jako je shlukování a kategorizování se staly populární v této souvislosti. Apache Mahout je rámec, který nám pomáhá k dosažení škálovatelnosti.
In this document, Budu mluvit o Apache Mahut a jeho význam.
Úvod: Apache Mahout je open source projekt od Apache Software Foundation nebo ASF, který má primární cíl vytvořit učící algoritmus stroj. Představený skupina vývojářů z projektu Apache Lucene, Apache Mahout má za cíl -
- Budovat a podporovat komunitu uživatelů nebo přispěvatelů, takže přístup ke zdrojovému kódu pro rámec není omezen na malé skupině vývojářů.
- Zaměřit se na praktické problémy, spíše než neviditelných nebo neprokázaných otázkám.
- Předloží příslušnou dokumentaci.
Vlastnosti Apache Mahout:
Apache Mahout přichází s řadou vlastností a funkcí, zejména když hovoříme o seskupování a číslování Collaborative filtrování. Nejdůležitější znaky jsou uvedeny v -
- Ochutnejte Collaborative filtrování - Chuť je open source projekt pro kolaborativní filtrování. Je součástí rámce Mahut, který poskytuje algoritmů strojového učení o zintenzivnění našich aplikací. Chuť se používá pro osobní doporučení. V těchto dnech, kdy jsme se otevřít webové stránky najdeme spoustu doporučení týkajících se webové stránky, které jsme procházejí. Následující obrázek ukazuje architektura diagram chutí -
Ochutnejte architektura diagram
Figure 1: Ochutnejte architektura diagram
- Pro snížení povolené implementace - Několik mapreduce povolen seskupený implementace jsou podporovány v Mahout. To zahrnuje K-Průměrný, nejasný, Baldachýn
- Distribuované Navie Bayes a veřejných Navie Bayes - Apache Mahut má implementaci jak pro Navie Bayes a bezplatné Bayes. Pro jednoduchost Navie Bayes jsou označovány jako Bayes a zapůjčení jsou označovány jako CBayes. Bayes jsou použity v textu třídění, zatímco CBayes jsou prodloužením Bayes, které se používají v případě, že "datových souborů".
- To podporuje matice a další související vektorových knihovny.
Nastavení Apache Mahout:
Nastavení Apache Mahout je velmi jednoduchá a může být prováděna v následujících krocích -
- Step 1 - Pro nastavení Apache Mahout, bychom měli mít nainstalován následující -
- JDK 1.6 or higher
- Mravenec 1.7 or higher
- Maven 2.9 nebo vyšší - V případě, že chceme vybudovat ze zdrojového kódu
- Step 2 - Rozbalte soubor, sample.zip a zkopírovat obsah v nějaké složce říkat "Apache Mahout-příklady".
- Step 3 - Jděte uvnitř složky - "apache-Mahut-příklady" a spusťte následující -
- ant nainstalovat
Posledním krokem stáhne soubory Wikipedii a kompiluje kód.
Doporučení Engine:
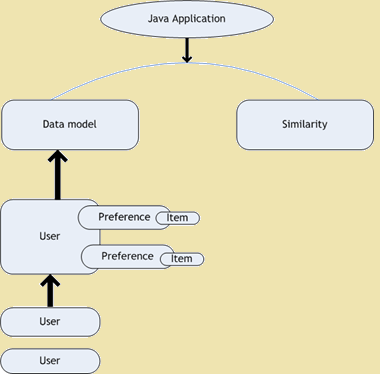
Doporučení motor je podtřídou filtračního systému informace, které mohou předpovědět hodnocením nebo uživatelských předvoleb může dát k položce. Mahout poskytuje nástroje a techniky, které jsou užitečné stavět doporučení motorů pomocí "Chuť" knihovnu. Použití Chuť knihovny můžeme postavit rychlý a flexibilní filtrování motor Collaborative. Chuť se skládá z následujících pěti základních složek, které pracují s uživateli, položky a předvolby -
- Datový model - Používá se jako úložný systém pro uživatele, položky a také preference.
- Uživatel Podobnost - To je rozhraní slouží k definování podobnosti mezi dvěma uživateli.
- Položka Podobnost - Rozhraní, které se používá k definování podobnosti mezi dvěma položkami.
- Recommender - Rozhraní, které se používá k doporučení.
- Uživatel Neighborhood - Rozhraní, které se používá k výpočtu a výpočet sousedství uživatelů stejné kategorie, které mohou být použity podle doporučujícím.
Použití těchto komponent a jejich implementaci, můžeme vybudovat komplexní systém doporučení. Toto doporučení motor může být použit v obou reálném čase doporučení a off-line doporučení. Real-time doporučení zvládne uživatelům až několik tisíc, zatímco doporučení v režimu offline zvládne uživatelům v mnohem vyšším počtem.
Clustering:
Mahout podporuje mnoho mechanismů clustering. Tyto algoritmy jsou psány v mapreduce. Každý z těchto algoritmů má svůj vlastní soubor cílů a kritérií. Mezi nejdůležitější jsou uvedeny v -
- Stříška - To je nejvíce rychlý clustering algoritmus použitý k vytvoření počáteční semen pro další algoritmy sdružování.
- K – Prostředky nebo Fuzzy k – znamená - Tento algoritmus vytváří K uskupení založených na vzdálenosti předmětů od středu předchozí iterace.
- Znamenat - Shift - Tento algoritmus nevyžaduje žádné předchozí informace o počtu klastrů. To může produkovat libovolnou clusteru, který může být zvýšen nebo snížen podle naší potřeby.
- Dirichlet - Tento algoritmus vytváří shluky tím, že kombinuje jeden nebo více modelů clusteru. Tak získáme výhodu pro výběr nejlepšího možného jeden z mnoha klastrů.
Mimo výše uvedených čtyř algoritmů uvedeny, nejčastěji používané je k - prostředky algoritmu. Ať už jde o jakýkoliv clustering algoritmus, musíme takto -
- Připravte vstup. If required, převést text do číselné reprezentace.
- Provést algoritmus podle svého výběru pomocí některého z připravených programů Hadoop k dispozici v Mahout.
- Řádně vyhodnotit výsledky.
- Opakovat tyto kroky v případě potřeby.
obsah Kategorizace:
Apache Mahout podporuje následující dva přístupy ke kategorizaci nebo klasifikaci obsahu. Ty jsou založeny zejména na Bayesovské statistiky -
- První přístup je přímočará mapreduce povolen Navie Bayes klasifikátor. Classifiers této kategorie jsou známy jako rychlý a přesný přesto, že má předpoklad, že data je zcela nezávislá. Tyto classifiers rozebrat, když velikost dat stoupá nebo data stane vzájemně závislé. Navie Bayesův klasifikátor je proces dvoudílný, který udržuje přehled o funkcích nebo prostě slova, která v souvislosti s dokumentem. Tento krok je známý jako trénink, který také vytváří model, při pohledu na příklady již nebyl klasifikován obsahu. Druhý krok, známý jako klasifikace, používá model, který je vytvořen během tréninku a obsah nového, neviditelné dokument. Proto, za účelem spuštění Mahout je klasifikátor, musíme nejprve trénovat model a potom použít model pro klasifikaci nový obsah.
- Druhý přístup, který je také známý jako doplňkové Naive Bayes, se snaží napravit některé problémy s přístupem Naive Bayes a stále zachovává jednoduchost a rychlost, kterou nabízí Navie Bayes.
Spuštění Navie Bayes klasifikátor:
Navie Bayes Classifier vyžaduje provedení následujících mravence cílů v rámci realizace -
- ant připravit-docs - To připravuje sadu dokumentů, které jsou nezbytné pro výcvik.
- ant připravit zkoušek docs - To připravuje sadu dokumentů, které jsou nezbytné pro testování.
- ant vlak - Jakmile jsou data školení a zkoušky stanovené, musíme spustit třídu TrainClassifier pomocí cíl - "ant vlak".
- ant zkouška - Po výše uvedených cílů byly úspěšně provedeny, musíme spustit tento cíl, který bere vstupní vzorek doklady a snaží se je zařadit na základě modelu, který byl vytvořen při tréninku.
Summary: V tomto článku jsme viděli, že Apache Mahout je široce používán pro textovou klasifikaci pomocí algoritmů strojového učení. Tato technologie je stále roste a může být použit pro různé typy vývoj aplikací. Shrňme si naši diskusi v podobě následujícího kulky -
- Apache Mahout je open source projekt od Apache zavedena skupina vývojářů z projektu Apache Lucene. Hlavním cílem tohoto projektu je vytvořit algoritmus, který umí číst strojového jazyka.
- Apache Mahout má následující důležité vlastnosti -
- Ochutnejte Collaborative filtrování.
- implementace MapReduce povolen.
- Implementace pro oba Distributed Navie Bayes a bezplatné Navie Bayes.
- Podporuje matice a dalších knihoven související vektor na bázi.