Visió de conjunt: Amb tants marcs de desenvolupament en tot, es fa important que hem de ser capaços d'ampliar la nostra sol·licitud en qualsevol punt donat del temps. tècniques com l'agrupació i categorització màquina d'aprenentatge s'han fet populars en aquest context. Apache mahout és un marc que ens ajuda a aconseguir l'escalabilitat.
In this document, Vaig a parlar d'Apache mahout i la seva importància.
Introducció: Apache mahout és un projecte de codi obert d'Apache Software Foundation o ASF que té l'objectiu principal de crear algoritme d'aprenentatge automàtic. Introduït per un grup de desenvolupadors del projecte Apache Lucene, Apache mahout té l'objectiu de -
- A construir i donar suport a una comunitat d'usuaris o contribuents perquè l'accés al codi font per al marc no es limita a un petit grup de desenvolupadors.
- Centrar-se en els problemes pràctics, en lloc de qüestions que no es veuen o no provades.
- Presentar la documentació adequada.
Característiques d'Apache mahout:
Apache mahout ve amb una sèrie de característiques i funcionalitats especialment quan parlem de l'agrupació i el filtrat col·laboratiu. Les característiques més importants s'enumeren com sota -
- Sabor Filtrat Col·laboratiu - Gust és un projecte de codi obert per al filtratge col·laboratiu. És la part del marc mahout que proporciona algoritmes d'aprenentatge automàtic per ampliar les aplicacions dels nostres. El gust s'utilitza per obtenir recomanacions personals. En aquests dies quan vam obrir una pàgina web ens trobem amb un munt de recomanacions relacionades amb la pàgina web que estem navegant. La següent figura mostra el diagrama de l'arquitectura del Gust -
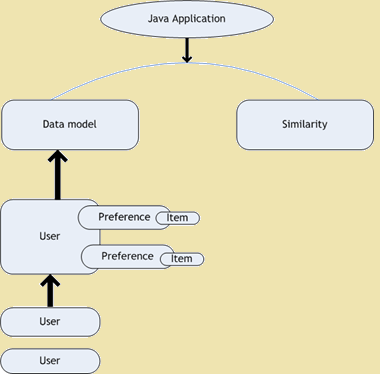
Sabor diagrama d'Arquitectura
Figure 1: Sabor diagrama d'Arquitectura
- MapReduce implementacions habilitats - Diversos MapReduce implementacions agrupades habilitats són compatibles amb mahout. això inclou K-media, borrós, dosser
- Distribuït naviliers Bayes i connexió naviliers Bayes - Apache mahout té l'aplicació per a tots dos naviliers Bayes i la cortesia de Bayes. Per simplicitat Bayes naviliers es coneixen com Bayes i la cortesia són referits com CBayes. Bayes s'utilitzen en la classificació de text, mentre que els CBayes són l'extensió de Bayes, que s'utilitzen en el cas de conjunts de dades ''.
- És compatible amb Matrix i altres biblioteques de vectors relacionats.
Configuració d'Apache mahout:
Configuració d'Apache mahout és molt simple i es pot dur a terme en els següents passos -
- Step 1 - Per tal de configurar Apache mahout, hem de tenir instal·lat el següent -
- JDK 1.6 or higher
- formiga 1.7 or higher
- Maven 2.9 o superior - En el cas que volem construir a partir del codi font
- Step 2 - Descomprimir l'arxiu, sample.zip i copiar el contingut d'alguna carpeta diuen "Apache-mahout-exemples".
- Step 3 - Anar dins de la carpeta - "Apache-mahout-exemples" i executeu el següent -
- formiga instal·lar
L'últim pas descarrega els arxius de Wikipedia i compila el codi.
motor de recomanació:
Recomanació del motor és una subclasse de sistema de filtrat d'informació que pot predir la qualificació o preferències d'usuari pot donar a un element. Mahout proporciona eines i tècniques que són útils per a construir motors de recomanació utilitzant la biblioteca 'Taste. L'ús de la biblioteca Gust podem construir un motor de filtratge col·laboratiu ràpida i flexible. El gust es compon dels següents cinc components primaris que treballen amb els usuaris, articles i preferències -
- Model de Dades - Això s'utilitza com un sistema d'emmagatzematge per als usuaris, articles i també les preferències.
- Similitud usuari - Aquesta és una interfície utilitzada per definir la similitud entre dos usuaris.
- Similitud articles - Una interfície que s'utilitza per definir la similitud entre dos articles.
- recomanador - Una interfície que s'utilitza per proporcionar recomanacions.
- Barri de l'usuari - Una interfície que s'utilitza per calcular i calcular un barri dels usuaris de mateixa categoria que poden ser utilitzats pel Recommenders.
L'ús d'aquests components i les seves implementacions, podem construir un complex sistema de recomanació. Aquest motor de recomanació es pot utilitzar en les dues recomanacions temps real i fora de línia recomanacions. recomanacions en temps real els usuaris poden gestionar fins a uns pocs milers, mentre que les recomanacions fora de línia els usuaris poden manejar molt més alt en el recompte.
l'agrupació:
Mahout suporta diversos mecanismes d'agrupació. Aquests algoritmes s'escriuen al mapa reduir. Cada un d'aquests algoritmes té el seu propi conjunt d'objectius i criteris. Els més importants s'enumeren com sota -
- canopy - Aquest és l'algoritme més ràpid agrupament utilitzat per a crear llavors inicials per altres algoritmes d'agrupament.
- k – Mitjans o Fuzzy k – significa - Aquest algoritme crea grups k en base a la distància dels articles des del centre de la iteració anterior.
- La mitjana - Maj - Aquest algoritme no requereix cap informació prèvia sobre el nombre d'agrupacions. Això pot produir un clúster arbitrària que pot ser augmentat o disminuït segons la nostra necessitat.
- Dirichlet - Aquest algoritme crea grups mitjançant la combinació d'un o més models de dispersió. D'aquesta manera obtenim un avantatge per a seleccionar la més adequada possible a partir d'una sèrie d'agrupacions.
Fora dels quatre algoritmes enumerats anteriorment, la més utilitzada és la k - significa algoritme. Ja es tracti de qualsevol algoritme d'agrupament, hem de seguir aquests passos -
- Preparar l'entrada. If required, convertir el text en representació numèrica.
- Executar l'algoritme de la seva elecció mitjançant l'ús de qualsevol dels programes de llistes de Hadoop disponible a mahout.
- Valorar adequadament els resultats.
- Iterar aquests passos si cal.
categorització de contingut:
Apache mahout suporta els següents dos enfocaments per categoritzar o classificar els continguts. Aquests es basen principalment en l'estadística bayesiana -
- El primer enfocament és recta cap endavant a reduir Mapa activar naviliers classificador de Bayes. Els classificadors d'aquesta categoria són coneguts per ser ràpid i precís tot i tenir el supòsit que les dades és completament independent. Aquests classificadors es descomponen quan la mida de les dades puja o les dades es torna més interdependent. Naviliers Bayes classificador és un procés de dues parts que manté un registre de les característiques o simplement paraules que associats amb un document. Aquest pas es coneix com la formació que també crea un model observant exemples de contingut ja classificada. El segon pas, conegut com classificació, utilitza el model que es crea durant la formació i el contingut d'un nou, document no vist. per tant, per tal d'executar classificador de mahout, primer hem d'entrenar el model i aleshores utilitzar el model per classificar els nous continguts.
- El segon enfocament, que també es coneix com a complementària Bayes Naive, tracta de corregir alguns dels problemes amb l'enfocament bayesià i encara manté la simplicitat i velocitat oferta per naviliers Bayes.
L'execució de la naviliers classificador de Bayes:
El naviliers classificador de Bayes requereix l'execució de les següents tasques ant per executar -
- formiga-docs preparar - Això prepara el conjunt de documents que són necessaris per a la formació.
- formiga preparar-prova-docs - Això prepara el conjunt de documents que es requereixen per a la prova.
- tren de formigues - Una vegada que s'estableixen les dades d'entrenament i prova, hem d'executar la classe TrainClassifier utilitzant l'objectiu - "tren de la formiga".
- ant test - Una vegada que els objectius anteriorment s'han realitzat amb èxit, hem d'executar aquest objectiu que pren els documents d'entrada de mostra i intenta classificar-los en base al model que es va crear durant l'entrenament.
Summary: En aquest article hem vist que Apache mahout és àmpliament utilitzat per a la classificació de text mitjançant l'ús d'algoritmes d'aprenentatge automàtic. La tecnologia encara està creixent i es pot utilitzar per a diferents tipus de desenvolupament d'aplicacions. Fem un resum de la nostra discussió en forma de bales següent -
- Apache mahout és un projecte de codi obert d'Apache introduït per un grup de desenvolupadors del projecte Apache Lucene. Objectiu principal d'aquest projecte és crear algoritme que pot llegir el llenguatge de màquina.
- Apache mahout té les següents característiques importants -
- Sabor Filtrat Col·laboratiu.
- implementacions permès MapReduce.
- Aplicació de les dues distribuïdes naviliers Bayes i connexió naviliers Bayes.
- És compatible amb la matriu i altres llibreries basades vectorial relacionada.