Oorsig: Met so baie ontwikkelingsraamwerke rondom, dit belangrik dat ons moet in staat wees om die skaal van ons aansoek op enige gegewe tydstip. Masjienleer tegnieke soos groepering en kategorisering het gewild geword in hierdie konteks. Apache olifanten drijver is 'n raamwerk wat ons help om scalability te bereik.
In this document, Ek sal praat oor Apache olifanten drijver en die belangrikheid daarvan.
Inleiding: Apache olifanten drijver is 'n oop bron projek van Apache Software Foundation of ASF wat die primêre doel van die skep van masjienleer algoritme het. Wat deur 'n groep van die ontwikkelaars van die Apache Lucene projek, Apache olifanten drijver het ten doel om -
- Bou en te ondersteun 'n gemeenskap van gebruikers of bydraers sodat toegang tot die bronkode vir die raamwerk is nie beperk tot 'n klein groepie van die ontwikkelaars.
- Fokus op die praktiese probleme, eerder as onsigbare of onbewese sake.
- Voorsien toepaslike dokumentasie.
Kenmerke van Apache olifanten drijver:
Apache olifanten drijver kom met 'n verskeidenheid van funksies en veral wanneer ons praat oor Groepering en Collaborative Filtering. Die belangrikste kenmerke is gelys as onder -
- Proe Collaborative Filtering - smaak is 'n oop bron projek vir samewerkende filtrering. Dit is die deel van die olifanten drijver raamwerk wat masjienleer algoritmes te vergroot ons programme bied. Smaak word gebruik vir persoonlike aanbevelings. Deesdae wanneer ons 'n webwerf oop te maak, vind ons baie aanbevelings met betrekking tot die webwerf wat ons is op. Die volgende figuur toon die argitektuur diagram van smaak -
Proe Architecture diagram
Figure 1: Proe Architecture diagram
- Kaart verminder in staat gestel implementering - Verskeie kaart verminder in staat gestel gegroepeer implementering ondersteun in olifanten drijver. dit sluit K-gemiddeld, fuzzy, Kap
- Versprei Navie Bayes en komplimentêre Navie Bayes - Apache olifanten drijver het die implementering van beide Navie Bayes en komplimentêre Bayes. Vir eenvoud Navie Bayes verwys word as Bayes en komplimentêre verwys word as CBayes. Bayes gebruik word in teks formaat, terwyl die CBayes is verlenging van Bayes wat gebruik word in die geval van 'Datastelle'.
- Dit word ondersteun deur Matrix en ander verwante vektor biblioteke.
Die opstel van Apache olifanten drijver:
Die opstel van Apache olifanten drijver is baie eenvoudig en kan in die volgende stappe gedoen word -
- Step 1 - Ten einde vir die opstel van Apache olifanten drijver, Ons moet die volgende geïnstalleer -
- JDK 1.6 or higher
- ant 1.7 or higher
- Maven 2.9 of hoër - In geval wil ons bou uit die bron-kode
- Step 2 - Pak die lêer, sample.zip en kopieer die inhoud in 'n gids sê "Apache-olifanten drijver-voorbeelde".
- Step 3 - Gaan binne-in die gids - "Apache-olifanten drijver-voorbeelde" en hardloop die volgende -
- mier installeer
Die laaste stap afgelaai die Wikipedia lêers en stel die kode.
aanbeveling Motor:
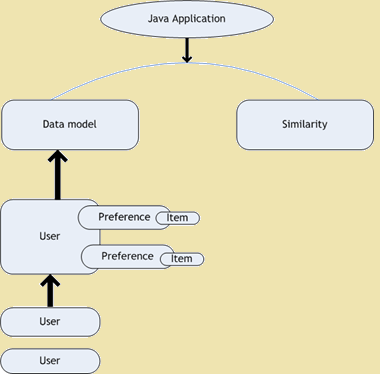
Aanbeveling enjin is 'n subklas van inligting filter stelsel wat die gradering of voorkeure gebruiker kan voorspel kan gee aan 'n item. Olifanten drijver bied gereedskap en tegnieke wat nuttig vir aanbeveling enjins met behulp van die "smaak" biblioteek te bou is. Die gebruik van Taste biblioteek kan ons 'n vinnige en buigsame Collaborative Filtering enjin te bou. Smaak bestaan uit die volgende vyf primêre komponente wat werk met gebruikers, items en voorkeure -
- Data Model - Dit word gebruik as 'n stoor stelsel vir gebruikers, items en ook voorkeure.
- Gebruikers Gelykvormigheid - Dit is 'n koppelvlak wat gebruik word om die ooreenkoms te definieer tussen twee gebruikers.
- Item Gelykvormigheid - 'N koppelvlak wat gebruik word om die ooreenkoms te definieer tussen twee items.
- Recommender - 'N koppelvlak wat gebruik word om aanbevelings te verskaf.
- Gebruikers omgewing - 'N koppelvlak wat gebruik word om te bereken en 'n woonbuurt van gebruikers van dieselfde kategorie wat gebruik kan word deur die aanbevelers bereken.
Die gebruik van hierdie komponente en hul implementering, Ons kan 'n komplekse aanbeveling stelsel te bou. Hierdie aanbeveling enjin gebruik kan word in beide real time aanbevelings en af aanbevelings. Real-time aanbevelings kan hanteer gebruikers tot enkele duisende terwyl die regte pad aanbevelings kan hanteer gebruikers in veel hoër telling.
groepering:
Olifanten drijver ondersteun baie groepering meganismes. Hierdie algoritmes is geskryf in kaart te verminder. Elkeen van hierdie algoritmes het hul eie stel doelwitte en kriteria. Die belangrikstes is gelys as onder -
- Kap - Dit is die mees vinnige groepering algoritme gebruik om die aanvanklike sade vir ander cluster algoritmes skep.
- k – Middel of fuzzy k – beteken - Hierdie algoritme skep k trosse gebaseer op die afstand van die items uit die middel van die vorige iterasie.
- Beteken - Shift - Hierdie algoritme geen vooraf inligting oor die aantal clusters vereis. Dit kan 'n arbitrêre cluster wat kan verhoog of verlaag soos per ons behoefte te produseer.
- Dirichlet - Hierdie algoritme skep trosse deur die kombinasie van een of meer cluster modelle. So kry ons 'n voordeel om die beste moontlike een van 'n aantal groepe te kies.
Uit die bogenoemde vier algoritmes gelys, die mees algemeen gebruik word is die k - beteken algoritme. Of dit nou 'n groepering algoritme, Ons moet soos volg te werk -
- Berei die insette. If required, omskep die teks in numeriese verteenwoordiging.
- Voer die algoritme van jou keuse deur die gebruik van enige van die Hadoop gereed programme wat beskikbaar is in olifanten drijver.
- Behoorlik die resultate te evalueer.
- Itereer hierdie stappe indien nodig.
inhoud te kategoriseer:
Apache olifanten drijver ondersteun die volgende twee benaderings tot kategoriseer of te klassifiseer die inhoud. Dit is hoofsaaklik gebaseer op Bayesiaanse statistiek -
- Die eerste benadering is reguit vorentoe Map verminder in staat gestel Navie Bayes klassifiseerder. Klassifiseerders van hierdie kategorie is bekend vinnig en akkuraat te wees ondanks die feit dat die aanname dat die data is heeltemal onafhanklik. Hierdie klassifiseerders breek wanneer die grootte van die data styg of data word interafhanklik. Navie Bayes klassifiseerder is 'n twee-deel proses wat 'n spoor van die funksies of net woorde wat verband hou met 'n dokument hou. Hierdie stap staan bekend as opleiding wat ook skep 'n model deur te kyk na voorbeelde van reeds geklassifiseer inhoud. Die tweede stap, bekend as klassifikasie, maak gebruik van die model wat geskep is tydens die opleiding en die inhoud van 'n nuwe, onsigbare dokument. vandaar, ten einde olifanten drijver se klassifiseerder hardloop, moet ons eers die model op te lei en gebruik dan die model om nuwe inhoud te klassifiseer.
- Die tweede benadering, wat ook bekend staan as 'n aanvulling Naïef Bayes, probeer om 'n paar van die probleme met die Naïef Bayes benadering reg te stel en steeds in stand hou van die eenvoud en spoed wat aangebied word deur Navie Bayes.
Hardloop die Navie Bayes Classifier:
Die Navie Bayes Classifier vereis die uitvoering van die volgende mier teikens ten einde uit te voer -
- mier te berei-dokumente - Dit berei die stel dokumente wat vereis word vir die opleiding.
- mier te berei-toets-dokumente - Dit berei die stel dokumente wat vereis word vir die toets.
- mier trein - Sodra die opleiding en toetse data is ingestel, ons nodig het om die TrainClassifier klas hardloop met behulp van die teiken - "mier trein".
- mier toets - Sodra die bogenoemde doelwitte suksesvol uitgevoer, ons nodig het om hierdie teiken wat die monster insette dokumente neem en probeer om hulle te klassifiseer op grond van die model wat geskep is terwyl opleiding hardloop.
Summary: In hierdie artikel het ons gesien dat Apache olifanten drijver algemeen gebruik word vir die teks klassifikasie deur die gebruik van masjienleer algoritmes. Die tegnologie is nog steeds en kan gebruik word vir verskillende soorte aansoek ontwikkeling. Kom ons som ons bespreking in die vorm van volgende koeëls -
- Apache olifanten drijver is 'n oop bron projek van Apache wat deur 'n groep van die ontwikkelaars van die Apache Lucene projek. Primêre doel van hierdie projek is om algoritme wat masjientaal kan lees te skep.
- Apache olifanten drijver het die volgende belangrike funksies -
- Proe Collaborative Filtering.
- MapReduce enabled implementering.
- Implementering vir beide Distributed Navie Bayes en komplimentêre Navie Bayes.
- Ondersteun matriks en ander verwante vektor-gebaseerde biblioteke.