There has been a lot of hype around Hadoop for a long time. This hype was expected because Hadoop is perceived an extremely efficient big data processing tool. But time has come to look at some cold, hard facts. It is the time when the hype slowly dies down and businesses start to look at the Return on investment (ROI). A survey, conducted by Gartner, seems to show that a lot of companies are not planning to invest in Hadoop because they do not have the skills to use it or it is still deemed a user-unfriendly tool. There are other reasons as well. However, there is another group of people who are bullish about the prospects of Hadoop. If the situation seems confusing, it is because the attitude towards Hadoop is entering the phase of disillusionment from that of hype and that is natural. This is the time when businesses start to get realistic. This is the time when companies will objectively evaluate and use Hadoop.
Contrasting opinions on Hadoop adoption
As stated above, businesses are divided into two groups when it comes to Hadoop adoption: one group comprises enterprises that are reluctant, hesitant or circumspect when it comes to Hadoop adoption and the second group comprises enterprises that believe Hadoop is going to give good ROI. The attitude of the former group is reflected in the Gartner survey. Given below are the salient findings from the survey. Note that the survey findings were released in May, 2015. So, the results are pretty updated. The survey target audience comprised small and medium sized companies and C-level executives.
- 54% of the respondents do not plan to invest in Hadoop in the future.
- Just 18% of the respondents have plans to invest in Hadoop in the next two years.
- 26% of the respondents are deploying or experimenting with Hadoop.
- Companies that were reluctant or hesitant with Hadoop adoption cited skills shortage and user-unfriendliness as reasons for not thinking about Hadoop.
According to Merv Adrian (vice president at Gartner), “With such large incidence of organizations with no plans or already on their Hadoop journey, future demand for Hadoop looks fairly anemic over at least the next 24 months”. Moreover, the lack of near-term plans for Hadoop adoption suggests that, despite continuing enthusiasm for the big data phenomenon, demand for Hadoop specifically is not accelerating”. The main reasons for such a negative response to Hadoop are given below.
- Lack of Hadoop skills is an important constraint. Enterprises claim that their staff is not capable of using Hadoop. Hadoop, in its original form, has been largely confined to an exclusive group who could use it productively. Though a number of third-party tools are coming up to facilitate the use of Hadoop, even they are not easy to use. The main complaint against Hadoop and the third-party tools are they require new skills to be learnt which means additional investment. Existing skills cannot be used. Though training is available for these tools, experts believe that it will take another 2 to 3 years for these programs to gain credence.
- For many enterprises, Hadoop is not a priority. They think that Hadoop is overkill for the business problems it is supposed to solve. It is like deploying a missile to kill a group of flies. Also, the cost of Hadoop adoption is more than the benefit derived by solving the business problems enterprises are facing.
The second group is optimistic and confident about Hadoop adoption. There are companies that have started using Hadoop for their mainstream business and are reaping benefits. The main feature that is being used is real-time data processing. For example, companies can prevent fraud by analyzing data on a real-time basis. Companies are able to provide better products by analyzing on a real-time basis data feedback from their customers. They are receiving data from website-usage, video, Internet banking, social media and various other sources. In a survey conducted by TechValidate, 96% of the respondents are running several use cases on a single Hadoop cluster and among them, 20% are deploying nearly 50 use cases on a single Hadoop cluster. The survey revealed that 73% of the respondents are deploying their products and services and 59% are benefiting from reduced costs. Most of the above companies are MapR customers. According to Bryon Dover, a big data engineer with the Rubicon Project, “MapR gives me the reliability to process 3 trillion transactions a month with 99.999% uptime.”
What to make of the above findings?
The two extreme attitudes towards Hadoop adoption can be generally confusing but in the context of business cycle, this stage represents just another phase: that of enterprises leaving the hype stage and entering the evaluation stage. When there is hype, everything seems rosy but when there is evaluation, the disadvantages also come out. So, businesses are finding out how to best use Hadoop to solve their business problems or whether, Hadoop is at all required.
Hadoop needs to get over its exclusivity for sure because it is considered a difficult tool to use, available only to people who are specialized. There is no good front-end that makes it easy for people to process and analyze data. Also, there is a need to learn Hadoop and that needs additional investment. Third-party tools that claim to make Hadoop easy to use are not exactly living up to their claims. So, the whole offering needs modifications and it is going to take time. Basically, Hadoop needs to prove that it is easy to use.
Enterprises need to realize that one of the best uses of Hadoop is when you are processing data real time. That is where the second group of customers is reaping benefits. Batch processing is not where you should be focusing. Real time processing can enable you prevent frauds and offer customized products and services to your customers. Hadoop is not meant for static data. The image below shows that real-time usage is the biggest consideration for Hadoop.
In this context, it is pertinent to mention Apache Spark which has been doing a stellar job analyzing big data real time. It gives you a unified and comprehensive framework that helps you to manage huge data sets from variety of sources in real-time basis. The biggest advantage with Spark is that you can rapidly write applications in Python, Java or Scala and has more than 80 high-level operators. It also supports SQL queries, machine learning, streaming data and processing of graph data, other than Map and Reduce operations. In a nutshell, it can prove to be an effective real-time processing application.
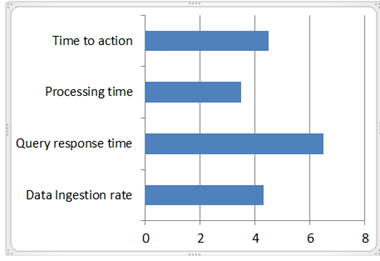
Real time usage of Hadoop
Image1: Real time usage of Hadoop
Any adoption of a new technology takes time. Hype and adoption are different things. It is quite possible that a percentage of the 57% of the respondents of the Gartner survey who did not plan to invest in Hadoop may do so after some time as Hadoop enters the mainstream production stage of many companies and its benefits start showing. This is especially after new technologies of products start to make Hadoop more usable. The SQL on Hadoop, for example, may be just the starting point of making Hadoop more accessible to a wider community.
Summary
The indifference towards Hadoop does not make it an unproductive tool. It is only that businesses are still unfamiliar with its ways. As MapR customers will corroborate, you need to identify how to best use Hadoop for solving your business problems. Using it for real-time data processing in the mainstream production appears to be the way to go. Similarly, there are other benefits too that still seem undiscovered. Of course, much around Hadoop and its ecosystem needs to change. It needs to be more accessible to anyone who wants to use it. The slow adoption rate of Hadoop could turn out into an acceptable proposition after 2 to 3 years.