Overview:
Hadoop is a platform that is almost synonymous with Big Data. It is basically an open source framework that allows the storage and processing of clustered data-sets on a large scale. Primarily, the Hadoop architecture is known to comprise of four major modules, which are HDFS (Hadoop Distributed File System), Hadoop Common, YARN and MapReduce. Each one of these modules is set to perform certain specific tasks, which come together as a whole to meet data processing requirements. One of the key aspects to production success is the Hadoop architecture. This architecture offers several key features that are responsible for its popularity over other frameworks as of now. However, there are also a few other things to consider for the successful implementation of Hadoop. This means, it isn’t just about having a proper storage system of records or the 24×7 running of applications, but also how it integrates with the overall architecture and tools of an enterprise.
This article shall largely discuss the Hadoop architecture in detail along with the advantages each module offers. We will also cover production success issues.
Following is a simple Hadoop architecture diagram for 2.0 versions
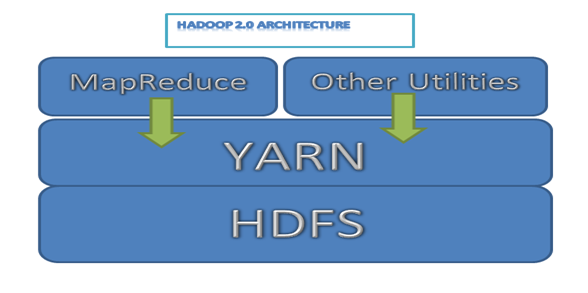
Hadoop 2.0 architecture
Image 1: Hadoop 2.0 architecture
HDFS Architecture
As mentioned already, Hadoop HDFS surely is one of the key components of the entire framework. It is the module which is tasked with providing a reliable, permanent and distributed storage system across several nodes that are present in a Hadoop cluster.
Now, a cluster usually consists of several nodes that are linked together to form one complete file system. All of the data that needs to be stored is at first broken into several small chunks known as blocks. These blocks are then distributed and stored across several nodes of the cluster. This is the manner in which the Hadoop file system is constructed and it has certain advantages as well.
Let us have a look at the other features of HDFS.
Scalable
Due to the presence of distributed file system architecture, Hadoop’s map and reduce functions work like a breeze. These functions can be easily executed on small subsets of the original data, thereby offering tremendous scalability. This is also an added advantage for businesses, as they can just add servers linearly, when their data seems to grow.
Flexible
Another very advantageous aspect of HDFS is its highly flexible nature in terms of storage of data. Being open source, Hadoop can easily run on commodity hardware, which saves costs tremendously. Also, the Hadoop file system can store any kind of data, whether it is structured, unstructured, formatted or even encoded.
Hadoop even makes it possible for unstructured data to be valuable to an organization during a decision making process, something that was practically unheard of before.
Reliable
The Hadoop file system is fault tolerant, which means that the data stored in HDFS is replicated to a minimum two other locations. Thus, in case there is a collapse of a system or two, there is always a third system that will have a copy of all your data. The system can then allocate workloads to this location and everything can work normally.
File I/O
The efficiency of any file system depends upon how it performs the I/O operations. In HDFS, data is added by creating a new file and write the data there. After this, the file is closed and the written data cannot be deleted or modified anymore. But new data can be appended by re-opening the file. So the basic foundation of HDFS is ‘Single write and multiple read’ model.
Block Placement
In HDFS, a file is a combination of multiple blocks. For adding a new block, NameNode assigns a unique block id and add it to the file. After this the new block is also replicated in multiple DataNodes.
HDFS block placement policy is configurable, so the users can experiment with different alternatives to get optimized solutions. By default, HDFS block placement policy tries to minimize the write cost and maximize the read performance, availability and reliability. To implement this, when a new block is added to a file, the first replica is placed on the same node where the writer is present. After this, the 2nd and 3rd replica is positioned on two different nodes in a separate rack. Now the rest of the replicas are placed randomly. But the restriction is that, one node cannot keep more than one replica and one rack cannot keep more than two replicas.
Following image shows a typical case of replica placements in a rack environment (as described in the above section)
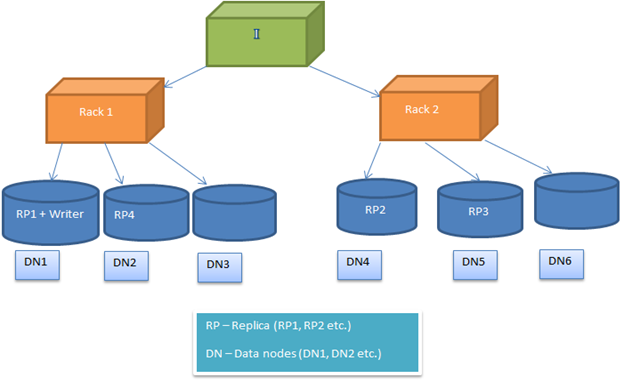
replica placement
Image2: Shows replica placement in a two rack environment
Hadoop Common/Hadoop Core
Hadoop common consists of the common set of utilities to support Hadoop architecture. These are basically base APIs to help other modules communicate with each other. It is also considered as an important part of Hadoop architecture like HDFS, MapReduce and YARN. It provides an abstraction on top of the underlying core features like file system, OS etc.
YARN Infrastructure
YARN, or ‘Yet Another Resource Negotiator’, is the module in Hadoop that is responsible for the management of computational resources. As such, it allocates CPUs or memory, based on the task that is at hand. Now, YARN is primarily made up of two major parts – the Resource Manager and the Node Manager.
- Resource Manager
The Resource Manager, which is also referred to as the master, has a single presence in a cluster and runs several services. It keeps track of where the workers are located and also manages the Resource Scheduler, which assigns resources.
- Node Manager
The Node Manager happens to be the worker of the infrastructure and there may be many of them in a Hadoop cluster. Each of these Node Managers offer resources to the cluster. Its capacity of resources is measured in the form of memory and vcores (share of CPU cores). The Resource Manager utilizes resources from the Node Manager, when it needs to run a task.
Hadoop YARN has certain very advantageous aspects that make it an important part of the architecture. These have been outlined in detail.
Multi-tenancy
One of Hadoop YARN’s biggest advantages is that it supports dynamic resource management. Despite sharing the resources of the same cluster, it is capable of running multiple engines and workloads. And, just like HDFS, YARN is also highly scalable, which offers massive scheduling capabilities, no matter what the workload may be.
Robustness
Hadoop YARN offers robustness, which allows you to open up your data to a variety of tools and technologies that can help you get the best out of data processing. Its ecosystem is well setup to meet the needs of various developers and also organizations of small and large scale.
In fact, Hadoop at present comes with several known projects such as Hive, MapReduce, Zookeeper, HBase, HCatalog, and a lot more. Also, as the market for Hadoop keeps expanding, newer tools are added to this count every day.
Following is a typical YARN architecture diagram.
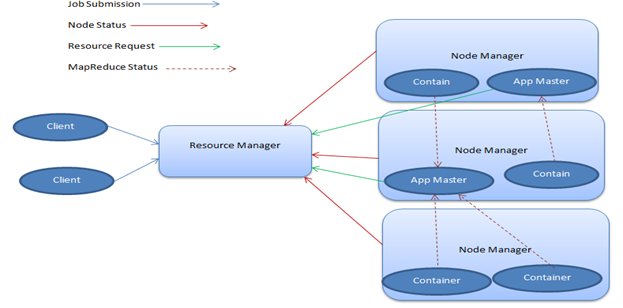
YARN Architecture diagram
Image3: YARN Architecture diagram
MapReduce Framework
MapReduce is said to be the heart of the Hadoop system. It is the programming framework that allows for the writing of applications for parallel processing of large data-sets available across several hundreds or thousands of servers in a Hadoop cluster.
The basic idea behind its working is the mapping and reducing of tasks. The Map function is responsible for the filtering and sorting of data, while the Reduce function carries out certain summary operations. MapReduce too arrives with its fair share of important aspects that aid in achieving production success, which are
Flexibility
MapReduce can process data of all types, whether it is structured, semi-structured or unstructured. This is one of the key aspects that make it an important part of the entire Hadoop architecture.
Accessibility
A wide range of languages is supported by MapReduce, which permits developers to work comfortably. In fact, MapReduce provides support for Java, Python and C++, and also for high-level languages such as Apache Pig and Hive.
Scalability
Being an integral part of the Hadoop architecture, MapReduce has been perfectly designed in a manner that it matches the massive scalability levels offered by HDFS. This ensures unlimited data processing, all under one complete platform.
How Hadoop components ensure production success?
In a production environment, scalability is one of the main criteria for business success. Because, if the application cannot scale (which runs on HDFS) during peak hours, then it will not be able to support increasing number of customers. As a result the business will lose money. So, from architectural point of view it is very important to have scalable storage and processing capabilities, which Hadoop can provide with its distributed file system (HDFS).
The other HDFS features like flexibility for supporting any type of data; reliability (fault tolerant) in case of a system collapse also adds value to a production environment. File I/O and block placement is also important as it supports data management very efficiently in a clustered environment. So we can conclude that the production success of any Hadoop application majorly depends upon the HDFS architecture itself.
In a typical cluster of 4000 nodes, we can have around 65 million files and 80 million blocks. Each block is having 3 replicas, so each node will have 60,000 blocks. This is a typical case at Yahoo data management. So it gives a fare idea about clustered environment and data storage.
YARN architecture provides an efficient resource management which is introduces in Hadoop 2.0 architecture. It ensures proper resource management in production environment.
Apart from the components, MapReduce programming helps in parallel processing of data in a distributed environment. So a faster processing is achieved in production system to support real world demands.
Conclusion
It is well known that Big Data is set to dominate the upcoming times in data processing, and with the Hadoop ecosystem it is thriving at present, it is also expected to be the frontrunner in the domain. Almost all data-based tools are making their way with Hadoop, in order to counter the challenges expected to be faced in the near future. Hadoop architecture is built to manage these huge volumes of data in a distributed environment. Each and every component of Hadoop platform is made to handle specific types of functionalities. So, as a whole it ensures production success of any bigdata application. But we also need to remember that the associated bigdata technologies also play an important role in application deployment and its success in real life scenarios.