Overview: We are well aware of the features of Hadoop and HDFS. In this document we will talk about the HDFS federation which helps us to enhance an existing HDFS architecture. It provides a clear separation between namespace and storage thus enables scalability and isolation at the cluster level.
Introduction: Hadoop federation separates the namespace layer and storage layer. It enables the block storage layer. It also expands the architecture of an existing HDFS cluster to allow new implementations and use cases. The current HDFS architecture has two layers –
- Namespace – This layer manages files, directories and blocks. This layer supports the basic file system operations e.g. listing of files, creation of files, modification of files and deletion of files and folders.
- Block Storage – This layer has two parts –
- Block Management This manages the datanodes in the cluster and provides operations like creation, deletion, modification and search. It also takes care of the replication management.
- Physical Storage This stores the blocks and provides access for read or write operations.
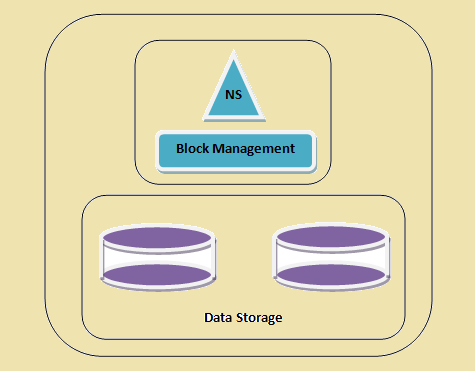
An HDFS cluster
Figure 1: An HDFS cluster
In the current HDFS architecture, we have only one namespace for the whole cluster which is managed by a single name node. Using this approach it becomes easier to implement the HDFS cluster. This layering of architecture works fine for smaller setups while for larger organizations where a huge volume of data needs to be taken care at a rapid speed, e.g. yahoo and Facebook it was found that this approach has some limitations which are handled by the Hadoop federation. So Hadoop federation can be defined as the advanced architecture to overcome the limitations of current HDFS implementation.
Let us check the limitations as explained below –
- Tightly coupled Block Storage and Namespace – In the current architecture the block storage and the Namespace are tightly coupled which makes the alternate implementations of name nodes challenging and restricts other services to use the block storage directly.
- Namespace Scalability – The HDFS cluster scales horizontally by adding datanodes but we can’t add more namespace to an existing cluster horizontally. We can scale namespace vertically on a single namenode. The namenode stores the complete file system metadata within its memory which limits the number of blocks, files and directories to be supported on the file system that needs to be accommodated in the memory of the single namenode.
- Performance – The current file system operations are limited to the throughput of a single name node which at present supports 60000 concurrent tasks. But the new coming map reduce from Apache will have a support for more than 100000 concurrent tasks and thus will require multiple nodes.
- Isolation – In general the HDFS deployments are available on a multi-tenant environment where a single cluster is shared by multiple organizations. In this setup a separate namespace is not possible for one application or one organization.
HDFS Federation:
Hadoop federation allows scaling the name service horizontally. It uses several namenodes or namespaces which are independent of each other. These independent namenodes are federated i.e. they don’t require inter coordination. These datanodes are used as common storage by all the namenodes. Each datanode is registered with all the namenodes in the cluster. These datanodes send periodic reports and responds to the commands from the name nodes. We have a block pool which is a set of blocks that belong to a single namespace. In a cluster, the datanodes stores blocks for all the block pools. Each block pool is managed independently. This enables the name space to generate block ids for new blocks without informing other namespaces. If one namenode fails for any reason, the datanode keeps on serving from other namenodes.
One namespace and its block are collectively called Namespace Volume. When a namespace or a namenode is deleted the corresponding block pool at the datanode is deleted automatically. In the process of cluster up-gradation, each namespace volume is upgraded as a unit.
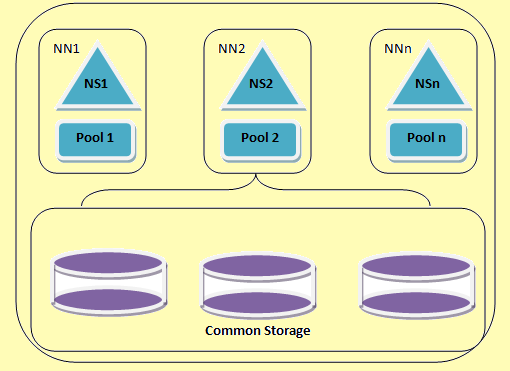
An HDFS federation architecture
Figure 2: An HDFS federation architecture
Benefits of Hadoop Federation:
Hadoop federation comes up with some advantages and benefits which are listed as under –
- Scalability and Isolation – Multiple namenodes horizontally scales up in the file system namespace. This actually separates namespace volumes for users and categories of application and provides an absolute isolation.
- Generic Storage Service – The block level pool abstraction allows the architecture to build new file systems on top of block storage. We can easily build new applications on the block storage layer without using the file system interface. Customized categories of block pool can also be built which are different from the default block pool.
- Simple Design – Namenodes and namespaces are independent of each other. There is hardly any scenario which requires changing the existing name nodes. Each name node is built to be robust. Federation is also backward compatible. It easily integrates with the existing single node deployments which work without any configuration changes.
Configuring an HDFS Federation:
Configuration of Hadoop Federation is designed in such a way that all the nodes in the cluster have the same configuration. The configuration is carried out in the following steps –
- Step 1 – The following parameters needs to be added in the existing configuration –
- nameservices – This is configured with a list of comma separated NameServiceIDs. This parameter is used by Datanodes to determine all the namenodes in the cluster.
- Step 2 – The following configurations needs to be suffixed with the corresponding name service ID into the common configuration file.
- Namenode
- Secondary NameNode
- BackupNode
A sample configuration file for two namenodes is shown below –
Listing 1: A Sample configuration file for two nodes
[Code]
<configuration>
<property>
<name>dfs.nameservices</name>
<value>ns1,ns2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1</name>
<value>nn-host1:6600</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1</name>
<value>nn-host1:8080</value>
</property>
<property>
<name>dfs.namenode.secondaryhttp-address.ns1</name>
<value>snn-host1:8080</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2</name>
<value>nn-host2:6600</value>
</property>
<property>
<name>dfs.namenode.http-address.ns2</name>
<value>nn-host2:8080</value>
</property>
<property>
<name>dfs.namenode.secondaryhttp-address.ns2</name>
<value>snn-host2:8080</value>
</property>
</configuration>
[/Code]
Formatting the Namenode: Let us the commands to format namenode.
- Step 1 – A single name node can be formatted using the following –
$HADOOP_USER_HOME/bin/hdfs namenode -format [-clusterId <cluster_id>]
The cluster id should be unique and must not conflict with any other exiting cluster id. If not provided, a unique cluster id is generated at the time of formatting.
- Step 2 – Additional namenode can be formatted using the following command –
$HADOOP_PREFIX_HOME/bin/hdfs namenode -format -clusterId <cluster_id>
It is important here that the cluster id mentioned here should be the same of that mentioned in the step 1. If these two are different, the additional namenode won’t be the part of the federated cluster.
Starting and stopping the cluster: Let us check the commands to start and stop the cluster.
- Start the cluster – The cluster can be started by executing the following command –
$HADOOP_PREFIX_HOME/bin/start-dfs.sh
- Stop the cluster – The cluster can be stopped by executing the following command –
$HADOOP_PREFIX_HOME/bin/start-dfs.sh
Add a new namenode to an existing cluster: We have already described that multiple name node is at the heart of Hadoop federation. So it is important to understand the steps to add new name nodes and scale horizontally.
The following steps are needed to add new namenodes –
- The configuration parameter – nameservices needs to be added in the configuration.
- NameServiceID must be suffixed in the configuration
- New Namenode related to the config must be added in the configuration files.
- The configuration file should be propagated to all the nodes in the cluster.
- Start the new namenode and the secondary namenode
- Refresh the other datanodes to pick the newly added namenode by running the following command –
o $HADOOP_PREFIX_HOME/bin/hdfs dfadmin -refreshNameNode <datanode_host_name>:<datanode_rpc_port>
- The above command must be executed against all datanodes on the cluster.
Summary: HDFS federation has been introduced to overcome the limitations of earlier HDFS implementation. Adding scalability at the namespace layer is the most important feature of HDFS federation architecture. But HDFS federation is also backward compatible, so the single namenode configuration will also work without any changes.
Let us summarize our discussion in the form of following bullets
- HDFS federation separates the namenode layer and the storage layer.
- HDFS federation is designed to overcome the limitations of the single node HDFS architecture where the storage can scale up horizontally not the namespace.
- HDFS federation comes up with following advantages –
- Isolation
- Scalability
- Simple Design
- HDFS configuration is very simple and is also easy to manage.