
Exploring NLP and Python
Introduction:
Let’s start the article with a very simple question, “What do you think is natural language?” Most of you would say that natural language is something in which we can communicate easily and hassle free with other person who can understand that language. Natural language for different peoples can be different such as Hindi, English, Bengali, Spanish, and French etc. Now, if we talk about interacting with machines then the question arises can we communicate in our natural language that easily with machines too? It’s no longer just possible in Sci-Fi movies, we are doing that every day now, and it has been made possible by computer science technology called Natural Language Processing (NLP).
Basically, NLP is that field of computer science, artificial intelligence and computational linguistic which is concerned with Human-Machine interaction. It makes the machines understand human speech as it is spoken. In other words, we can say that NLP applications allow users to communicate with machines in their own natural language.
Let’s look at some of areas where we are using NLP every day.
Spam Filtering: This is one of the most important applications of NLP. Everybody wants only the useful emails in his/her inbox among the hundreds of emails coming daily. That is why email provider filters the email by calculating its likelihood of being spam based on its content. It can be done with the help of Naïve based spam filtering.
Virtual Digital assistants: VDA (Virtual digital assistant) technology is an automated software applications or platform that assists the human user by understanding natural language. Now days, with the help of virtual assistants like Google’s Now, Apple’s Siri and Microsoft’s Cortana we can do everything like getting a particular recipe, finding a hotel, the directions to reach at a particular place etc. by simply speaking.
Skype Translator: Skype translator uses NLP for on-the-fly translation to interpret live speech in real time across a number of languages. It is really useful as people can communicate using the language in which they are comfortable.
Google Translate: Google translate uses statistical machine translation for translating the word along with understanding the meaning of sentence. A learning algorithm makes it learn and improve the translation whenever a user helps to make a correct translation.
News feeds on social websites: For this we can take the example of Facebook news feed where you will see the ads according to your interest. Basically, news feed algorithms understands our interest using NLP and feed our social website page with related Ads.
Python for NLP implementations:
There are various open source NLP libraries like Natural Language Toolkit (NLTK), Apache OpenNLP, Stanford NLP suite, Gate NLP library etc. for implementing NLP. Among them, NLTK, written in Python, is the most popular library. In this article, we are also going to use NLTK for handling the challenges of NLP. Before using it, we need to install, import and download it.
Installing NLTK:
NLTK can be installed with the help of pip command as follows:
pip install nltk
Other than that, we can directly install it from the link: https://pypi.python.org/pypi/nltk
Importing NLTK:
Importing NLTK is basically used to check if it is installed successfully or not. We can write the following command on our python terminal to import NLTK:
>>> import nltk
After running the above command, if there is no error from python then it means NLTK library is successfully installed.
Downloading NLTK package:
Now, after importing NLTK, we need to download NLTK package. We can write the following command on our python terminal to download NLTK package:
>>> nltk.download()
After running the above command, we will get NLTK downloader as shown in the following image:
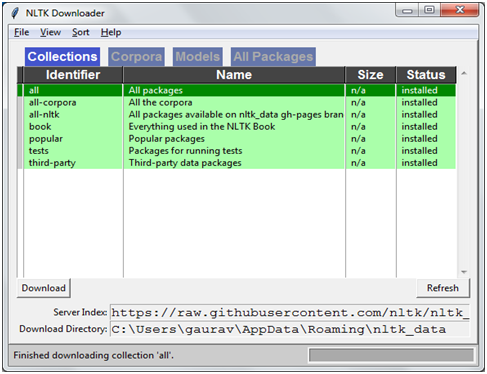
Image 1 : NLTK Downloader
Click on the download button and we will be able to start with NLTK package shortly as it would not take much time to install these small packages. It is recommended that we must download all the packages because we will get all of tokenizers, chunkers, all of the corpora and other algorithms too.
Key challenges in NLP & their solutions using NLTK:
Working with NLP applications can be very interesting but at the same time challenging. The most difficult challenge is to get good structured data. In today’s scenario, we have approximately 80% of the data in unstructured form which is being generated continuously from the activities like post on social media, customer reviews, news, blogs etc. Almost every activity of our on web is producing some data, mostly unstructured.
Tokenization: It is the process of splitting words & sentences, the smaller parts generally called tokens from the given text. We have two forms of tokenization namely word tokenizers and sentence tokenizers. As the name suggests, word tokenizer splits the text into words and sentence tokenizer splits the text into sentences. NLTK provides two different functions, word_tokenize() and sent_tokenize() for word and sentence tokenizers respectively.
Listing 1: Code for splitting words and sentences from the text by using word_tokenize() and sent_tokenize() respectively:
[code]
import nltk
from nltk.tokenize import word_tokenize
Sample_text = “My name is Ram. I am a atudent.”
print(word_tokenize(sample_text))
[/code]
Output: [‘My’, ‘name’, ‘is’, ‘Ram’, ‘.’, ‘I’, ‘am’, ‘a’, ‘student’, ‘.’]
[code]
import nltk
from nltk.tokenize import sent_tokenize
Sample_text = “My name is Ram. I am a atudent.”
print(sent_tokenize(sample_text))
[/code]
Output: [‘My name is Ram.’, ‘I am a student.’]
Stemming: Almost every language is inflected i.e. it is having lots of variations in the words. Here, the concept of variation means that there would be different forms of the same word like for example, ‘fishing’, ’fisher’ and ‘fished’. This is another challenge for NLP to make computer understand that these words are having the same base form say ‘fish’ for the above mentioned words.
The above problem can be solved by stemming programs which is also called stemming algorithms or stemmers. Stemming basically is the process of extracting the base or root form of the word. Julie Beth Lovins has written the first stemmer in 1968, which had great influence in this area of work.
NLTK provides three kinds of stemmers namely PorterStemmer, LancasterStemmer and SnowballStemmer for stemming process. All the three stemmers are using different algorithms and having different level of strictness. Applying these stemmers on the same word, we may get the different base forms as result.
Listing 2: Code for extracting the base of words by using PorterStemmer, LancasterStemmer and SnowballStemmer repectively:
[Code]
import nltk
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
word = “writing”
print(stemmer.stem(word))
[/Code]
Output:write
[Code]
import nltk
from nltk.stem import LancasterStemmer
stemmer = LancasterStemmer()
word = “writing”
print(stemmer.stem(word))
[/Code]
Output:writ
[Code]
import nltk
from nltk.stem import SnowballStemmer
stemmer = SnowballStemmer(“english”)
word = “writing”
print(stemmer.stem(word))
[/Code]
Output:write While using SnowballStemmer, we need to pass argument for language. In the above example we have used “English” as the argument. We can also check the different languages supported by SnowballStemmmer.
Listing 3: Code for getting the different languages supported by SnowballStemmer:
[Code]
import nltk
from nltk.tokenize import SnowballStemmer
print(” “.join(SnowballStemmer.languages))
[/Code]
Output:danish dutch english finnish french german hungarian italian norwegian porter portuguese romanian russian spanish swedish
Lemmatization: Lemmatization also gives us the base or root form of the words as stemming does. The lemmatization process uses the vocabulary and morphological analysis of words hence it gives actual words as output which is in contrast to the stemming process that often create non-existent words. The base form of any word produced by lemmatization is called lemma. NLTK provides WordNetLemmatizer for lemmatizing process.
Listing 4: Code for extracting the base of words by using WordNetLemmatizer:
[Code]
import nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
word = “better”
print(lemmatizer.stem(word))
[/Code]
Output:better
It takes the part of speech parameter ‘pos’ also. If we will not provide any pos parameter then by default the base word would be noun.
Listing 5: Code for extracting the base of words by using WordNetLemmatizer with pos parameter:
[Code]
import nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
word = “better”
print(lemmatizer.lemmatize(word,pos=”a”))
[/Code]
Output:
good
You can observe the difference between the output when we used WordNetLemmatizer without and with pos parameter in Listing 4 and Listing 5 respectively.
Chunking: It is the process of identifying the parts of speech and short phrases like noun phrases in the give text. To be more specific, chunking labels the tokens which is created by the process of tokenization. We have two forms of chunking namely chunking up, the object will be moving towards more general and language gets more abstract, and chunking down, the object will be moving towards more specific and language gets more penetrated.
Listing 6: Code for implementing the noun phrase chunking:
[Code]
import nltk
text=[(“a”,”DT”),(“beautiful”,”JJ”),(“women”,”NN”),(“was”,”VBP”),(“crossing”,”VBP”),(“the”,”DT”),(“road”,”NN”)]
grammar = “NP:{<DT>?<JJ>*<NN>}”
parser_chunking=nltk.RegexpParser(grammar)
parser_chunking.parse(text)
Output_chunk=parser_chunking.parse(text)
Output_chunk.draw()
[/Code]
Output:Tree(‘S’, [Tree(‘NP’, [(‘a’, ‘DT’), (‘beautiful’, ‘JJ’), (‘women’, ‘NN’)]), (‘was’, ‘VBP’), (‘crossing’, ‘VBP’), Tree(‘NP’, [(‘the’, ‘DT’), (‘road’, ‘NN’)])])
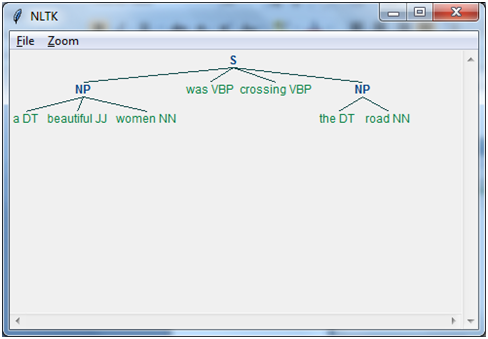
Image 2: Output of noun phrase chunking
End Note: In this article, I gave a brief introduction to Natural Language Procession (NLP) along with some of the key areas where it is being used. I also tried to explain how we can use NLTK package of Python for beating implementation challenges faced by us while working with NLP. If you come across any difficulty while working in NLP with Python, or you have any suggestions / feedback please feel free to post them in the comments below.
You may like to read : How deep learning is helping the industry to grow?
Another interesting article for you : Artificial Intelligence and Product development
Author Bio: Gaurav Leekha is a freelance technical content writer having 7+ years of teaching experience. His key areas of interests are AI, Machine Learning, Deep Learning, ANN, Speech Processing and Python programming. He is also serving as the reviewer of various national as well as internationals journals including International Journal of speech technology (IJST), Springer